Global Data Sharing/Referencing
As people develop visualizations and process their geospatial data around the
world, it becomes highly valuable to be able to share the data. There are
several forms which this can take.
- Referencing System / Metadata
- some way is needed to easily search the internet for data by spatial
location
- SRI's Proposed .geo Top-Level
Domain
- proposes to use the existing internet domain systems to make hosts
searchable by location
- this produces domain names like "11e21n.3e7n.30e10n.geo"
for a 1-by-1 minute area
- it has not yet been accepted as a TLD by ICANN
- the WorldBoard project (http://www.worldboard.org/ broken as of Jan. 2003) intends to define some standards for referencing
systems, which their site says are "currently being developed"
- Centralized Data Repositories
- the easiest way to collect and serve data is to have designated server(s)
which responds to queries and serves the data
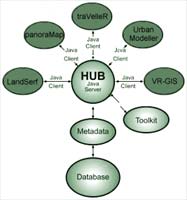
- Virtual Field Course (VFC)
(see Academic Terrain Projects)
- includes a hub which organizes a database with metadata, supporting
queries and supplying the data to clients
- server is built on Java, the protocol and source are potentially
open for people to adopt
- SRI's TerraVision (see
Noncommercial Terrain Projects)
- designed for many-to-many servers to clients
- claims to support "imagery, topography, weather data, buildings,
and other cultural features"
- the project was open-sourced in 2002, but did not find a following
- Central Reference Server / P2P Distributed Data
- i.e. "Napster for terrain"
- the central server would contain only the indexed metadata, with references
to location(s) where the data is located
- client software would need two protocols: one to query the server, one
to handle the P2P transfer
- this is more scalable and flexible than having designated server(s)
for the data, but requires clients to have high connectivity uptime
- Fully-Distributed
- i.e. "Gnutella for terrain"
- eventually, it may make sense to distribute the indexing of metadata
as well; no central chokepoint at all
- the index could either be thinly distributed, or some compromise for
efficiency such as limited caching the index at some nodes